
L’industria editoriale dei libri sta esplorando nuovi processi decisionali per predisporre rapidamente strategie suffragate da numerose e differenti fonti di dati. Un nuovo paradigma di sviluppo consente alle imprese di far fronte alla domanda interna ed esterna di informazioni, e definisce nuove interazioni con gli stakeholder della catena del valore editoriale: autori e lettori, editori, distributori, grossisti e librai… – L’analisi
Argomentare di big data è oggi di moda. Garantisce a chi ne parla attenzione mediatica e interesse dell’ascoltatore. Non necessariamente fornisce esperienze replicabili perché spesso si presentano progetti di dimensioni “big”, di imprese “big” e di budget “molto big”.
Big data sembra essere confinato in quelle imprese che operano nei settori industriali dove si generano decine o centinaia di milioni o di miliardi di byte come le società di telecomunicazione, i colossi bancari e i grandi retailer. E su queste dimensioni, in particolare per lo sviluppo dei progetti e l’adozione di piattaforme e infrastrutture, sono tarati costi e tempi.
In realtà, contrariamente a molte mode passeggere, big data influenza metodi, tecniche e strumenti adattandoli a differenti esigenze e dimensioni delle organizzazioni.
Così oggi si può realizzare un progetto di Data intelligence su Big Data gestito da organizzazioni snelle che per loro natura non hanno dimensioni confrontabili con le imprese dei settori descritti ma che possono avvantaggiarsi rapidamente dei risultati delle analisi condotte sui dati e delle informazioni da essi generati.
Se ne è parlato in modo ampio lo scorso ottobre a Francoforte in occasione della principale Fiera del Libro (leggi qui).
Big Data nell’Editoria dei Libri
I più recenti fenomeni tecnologici e di consumo dei dispositivi digitali hanno radicalmente modificato lo scenario informativo nel quale l’industria editoriale opera: la quantità dei dati (dovuta all’esplosione dei dispositivi digitali per interagire con il contenuto che generano dati ed alla loro accessibilità), la qualità (sui grandi numeri la qualità del dato si attesta su valori elevati e si attenua la necessità di interpretare il dato poiché esso esprime con maggiore chiarezza il suo significato), la frequenza con la quale sono generati (sono dati prodotti ininterrottamente), il formato (non solo dati strutturati che provengono da fonti certificate come i sistemi informativi aziendali, ma molti dati non strutturati sui quali non possono essere applicati modelli di analisi tradizionali), la velocità con la quale il singolo dato viene generato e diventa obsoleto.
Si consideri poi che negli ultimi anni sono comparse differenti modalità di fruizione dei contenuti: carta, eReader, tablet, smartphone, digital TV, cinema, car, wearable devices (come occhiali e orologi), solo per citarne alcuni. La frequenza con la quale ci spostiamo dall’uno all’altro realizza un continuum digitale nel quale siamo costantemente immersi.
Infine, ma non meno importante, gli analisti del mercato dell’industria libraria mostrano dati che, in assenza di informazioni da parte di alcuni (pochi per la verità) importanti operatori retail, presentano analisi statistiche incomplete.
E’ richiesto, quindi, un ripensamento radicale nella gestione integrata dei dati.
L’opera di un autore raggiunge il lettore attraverso l’editore, il distributore fisico o digitale, il grossista e, quindi, la libreria fisica o digitale. Questa filiera necessita, per ciascun attore, di sistemi complessi di gestione del dato basati, spesso, su unità di misura differenti. A titolo di esempio, è necessario comunicare in termini di volume di sell-in o sell-out, prezzo di copertina, defiscalizzato, scontato o promosso. Per alcuni canali poi, come ad esempio la Grande Distribuzione Organizzata, si definiscono convenzioni di misura del dato funzionali al canale di vendita e non all’integrazione con gli altri sistemi della filiera.
Un nuovo paradigma
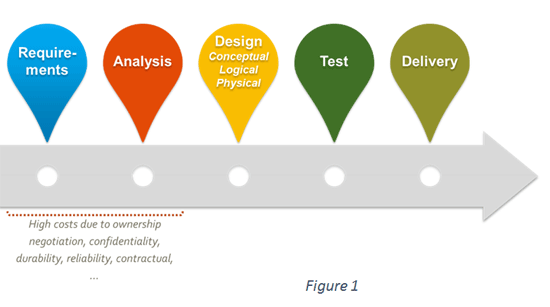
Lo sviluppo di progetti di data intelligence è ancora fondato su metodi nei quali le principali fasi si succedono in sequenza come in figura 1. Per le caratteristiche delle soluzioni e per gli stakeholder coinvolti le fasi di raccolta dei requisiti, l’analisi e la produzione delle specifiche assorbono ingenti costi di progetto e rappresentano il reale ostacolo allo sviluppo rapido delle soluzioni per il business.
I costi, economici e di tempo, così come la rapida obsolescenza delle soluzioni realizzate rendono questo approccio eccessivamente oneroso per quelle aziende che, pur dovendo gestire grandi quantità di dati come l’industria editoriale dei libri, non sono in grado di allocare adeguati investimenti.
In realtà, grazie alle nuove tecnologie, è possibile adottare nuovi metodi snelli e scalabili in un nuovo paradigma di sviluppo in cui anche la tradizionale definizione di progetto “on time, on budget and on spec” diventa “right time, right budget and beyond expectation”.
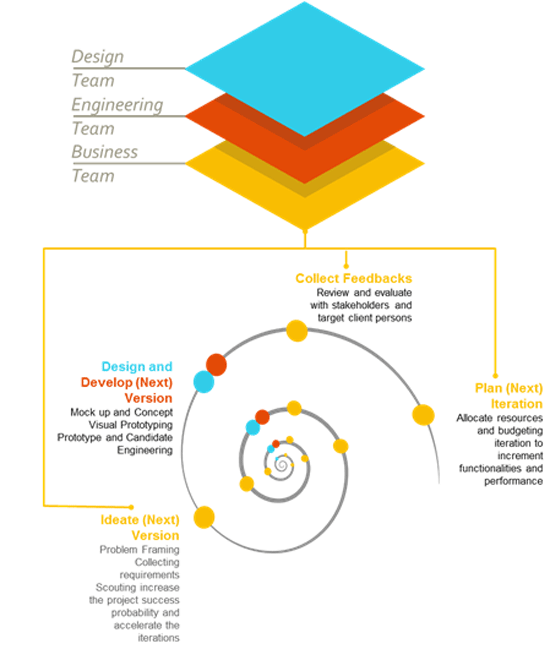
Figura 2
Questo nuovo paradigma di sviluppo è basato su metodi innovativi che utilizzano al meglio gli strumenti, le piattaforme e le tecnologie oggi disponibili. Il modello Spiral, rappresentato in figura 2, fornisce il più efficace riferimento. E’ caratterizzato da iterazioni molto rapide di raccolta dei dati, ideazione del prototipo, sviluppo basato su tecnologie avanzate, verifica del prototipo, pianificazione della nuova iterazione. Il risultato è una continua evoluzione della soluzione ed un ampliamento delle sorgenti informative integrate.
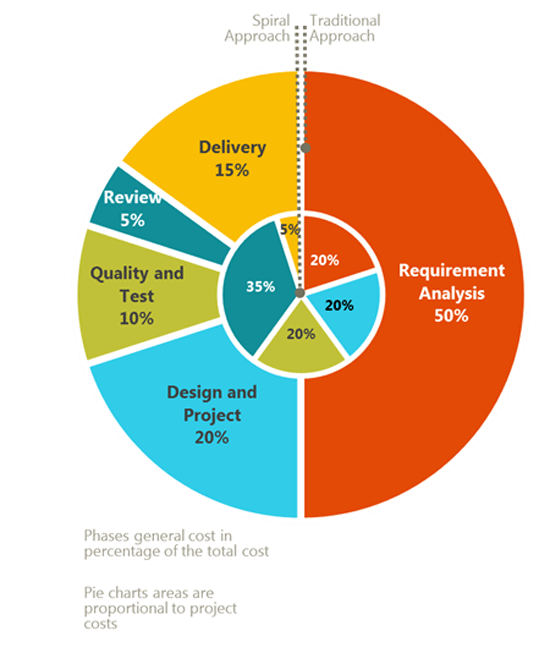 Figura 3
Figura 3
I risultati sperimentali hanno superato le aspettative in tempi e costi complessivi. E la distribuzione dello sforzo speso in ciascuna fase differisce in maniera considerevole rispetto al modello tradizionale. Infatti, se nell’approccio sequenziale il peso della sola fase di raccolta e analisi dei requisiti rappresenta circa il 50% del progetto complessivo, il modello Spiral presenta una distribuzione delle fasi di analisi dei requisiti, progettazione e sviluppo, e testing pari al 20% per ciascuna di esse (figura 3).
Gli stessi risultati sperimentali mostrano che la fase di review rappresenta la fase più importante con circa il 35%, rispetto a un 5% dell’approccio tradizionale, per la necessità di interagire con il committente in modo da raffinare il requisito e convergere incrementalmente e rapidamente alla soluzione desiderata.
Non è un caso che attori della Formula 1 forniscano ad altre industrie servizi di consulenza dedicata grazie alle competenze sviluppate nell’elaborazione di enormi flussi di dati generati dalle auto in corsa per determinare strategie competitive in tempo reale ed agire dinamicamente sulle tattiche e sulle configurazioni del sistema. www.businessweek.com/articles/2014-10-02/mclaren-uses-racing-expertise-in-data-driven-consulting
Data Intelligence sui Dig Data
L’industria editoriale dei libri necessita di un sistema dinamico di interrogazione dei dati che si adatti continuamente alle domande che nascono in funzione di mutevoli condizioni di mercato e impredicibili comportamenti dei clienti.
Si richiedono ad esempio correlazioni tra l’andamento delle vendite di titoli al lancio e le statistiche delle letture su eReader, tra le attività di comunicazione e marketing per interpretare il peso dei driver di successo commerciali o editoriali. O anche analizzare l’elasticità della domanda al variare del prezzo per i best-seller, i mid-seller, i low-seller e per i titoli che durano a lungo nel tempo (long-seller). O temi orientati alle fasi di produzione e distribuzione come ottimizzare i livelli di stampa e distribuzione dei libri per garantire massima disponibilità sui vari canali di vendita (GDO, librerie di catena, librerie indipendenti, …) e ridurre al minimo le rese sui vari canali. E come abilitare strategie di testing per ottimizzare le proposte editoriali online (cover, metadati, pricing, …). O chiedere, più genuinamente, quale combinazione di libri è più richiesta ed acquistata.
Alcune richieste possono sembrare ovvie per gli esperti che applicano modelli incontestati almeno fino ad oggi.
Eppure la lettura dei dati, quando provengono da molte fonti ed in grandi quantità, offre un risultato pratico mostrando correlazioni inattese e comportamenti di difficile spiegazione, anche per quegli stessi esperti.
Per cui sarebbe preferibile estrarre immediatamente la conoscenza dai dati, trovare le correlazioni, agire coerentemente e rapidamente, senza tentare complesse interpretazioni a priori. Ed è quanto soluzioni di Data Intelligence sui Big Data offrono.
Per realizzare una soluzione di Data Intelligence di questa portata senza incorrere nei problemi tipicamente di Information Technology di definizione, schematizzazione ed integrazione dei dati, oggi si adottano sistemi di archiviazione basati su data lake, cioè grandi archivi nei quali fare ingestion di dati transazionali e nei formati più disparati (pdf, word, ppt, excel, email, …). E si elaborano questi dati su piattaforme dinamiche in capacità di calcolo e spazio, rappresentando i risultati in una forma grafica intuitiva e orientata all’esigenza dello stakeholder con moderni strumenti di data visualization.
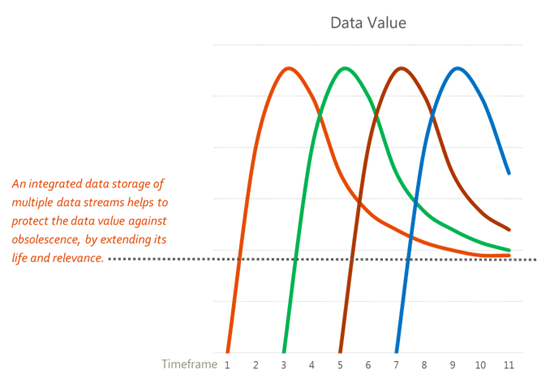 Figura 4
Figura 4
Con questo approccio si ottiene un duplice beneficio: visual data quality e prolungamento della vita e della rilevanza del dato nel tempo.
Progetti di Data Intelligence non sono progetti esclusivamente di Information Technology. E’ necessario valutare dove allocare capacità di calcolo e spazio necessario per archiviare le innumerevoli fonti di dati. Si tratta di stabilire quali piattaforme tecnologiche adottare ed i modelli di business dei servizi erogati così come definire ed accedere alle competenze necessarie per gestire questi nuovi sistemi e progettare con nuovi paradigmi.
E’ in sostanza modulare la dimensione di costo coerentemente alla complessità delle richieste degli stakeholder e dei volumi di dati, adattando i costi, siano essi consulenziali o di infrastruttura, alle esigenze delle organizzazioni (figura 5).
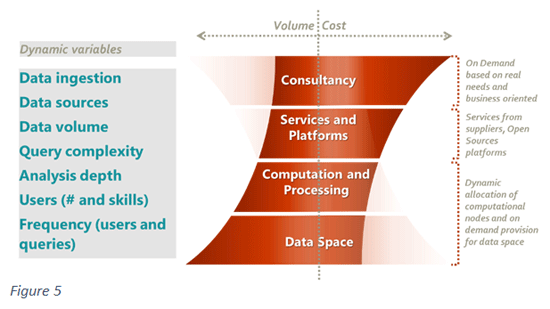
Così le barriere di ingresso alla data intelligence si abbassano. Un numero maggiore di organizzazioni e utenti può accede a strumenti che sembravano per pochi eletti, interagendo con ulteriori strumenti con gli stakeholders interni (editori, distributori, librai) ed esterni (autori, agenti e lettori).
E’ un nuovo mestiere che richiede una cultura di management in grado di selezionare tecnologie e metodi che consentono di modulare gli investimenti alle reali esigenze dell’industria editoriale di libri, di adottare nuovi paradgmi di sviluppo di soluzioni, di comprendere il gap di competenze e di risorse necessarie, di selezionare i talenti che possono guidare la trasformazione, di introdurre personale qualificato nell’elaborazione del dato. Questi scenari non possono essere circoscritti nell’ambito delle competenze IT. E’, molto più che nel passato, un processo strutturato di estrazione della conoscenza a partire dall’informazione e dal dato. E’, in estrema sintesi, un tema di qualità del capitale umano coinvolto che deve essere oggetto di attenzione e responsabilità delle principali figure di top management dell’industria editoriale.
*L’autore è Chief Digital Officer di Messaggerie Italiane S.p.A.


